Nov 4, 2025
When the Model Lies: Incident Response and Forensics for AI Systems
Whitepaper

Introduction: New Challenges in the AI Era
AI systems – from large language models (LLMs) and retrieval-augmented generation (RAG) pipelines to autonomous agents – are increasingly woven into business operations. With this integration comes a new class of security incidents and failures that don’t resemble traditional cyber attacks. In AI-driven incidents, the “exploit” might be a cleverly crafted sentence rather than malicious code[1]. For example, Samsung engineers accidentally leaked confidential source code by pasting it into ChatGPT[2]. In another case, a prankster tricked a car dealership’s sales chatbot into offering a $76,000 SUV for just $1[3]. We’ve also seen an AI misfire wipe out $100 billion in market value – Google’s Bard chatbot hallucinated an incorrect fact during a demo, tanking the stock price[4]. These incidents underscore that AI systems introduce failure modes and security breaches that are fundamentally different from those in traditional applications.
The need for AI-specific incident response (IR) and forensic readiness has become clear. Classic security tools and playbooks aren’t enough to investigate when a model “goes rogue” or leaks sensitive data. Technical leaders – CISOs, incident responders, AI/ML platform owners, SOC architects – must adapt their strategies to this new terrain. This white paper discusses why AI incidents require special preparation, illustrates how AI breaches unfold through real examples, and proposes a framework for effective incident response and forensics in AI-centric systems. It offers practical steps to ensure your security operations center (SOC) can detect, reconstruct, and recover from AI-related attacks or failures.
AI Incidents in the Wild: When Models Misbehave
To appreciate why AI-focused forensics is needed, consider the variety of public incidents involving AI systems in the last couple of years. These cases show that when AI fails, it fails in unfamiliar ways:
Data Leaks via AI Assistants: In May 2023, Samsung banned employees from using ChatGPT after discovering that engineers had inadvertently exposed confidential code and meeting notes to the model[2]. The prompt responses from ChatGPT could have retained or transmitted that sensitive data externally. A similar flaw was demonstrated in Slack’s AI beta – researchers showed they could trick the Slack GPT assistant into revealing contents of private channels via prompt injection[5], effectively turning an internal AI helper into a data exfiltration tool.
Prompt Injection Exploits: AI chatbots can be manipulated by malicious inputs. A notable example was a Chevrolet dealership’s chatbot that a user manipulated into “selling” a $76,000 Tahoe for $1[3]. The attacker simply crafted prompts that caused the bot to ignore its pricing rules. In another incident, an Air Canada customer service bot was duped into issuing an unduly large refund[6]. These real-world pranks highlight that prompt injection isn’t just theoretical – it can lead to tangible financial and business impact.
Hallucinations and Decision Failures: AI “hallucination” – the generation of false or misleading content – can create incident scenarios too. Google learned this when their Bard model confidently output false information about the James Webb Space Telescope, directly in a public demo. The mistake undermined trust and contributed to a $100 billion stock value drop for Alphabet[4]. In enterprise settings, a hallucinated answer might lead an autonomous agent to make bad decisions (e.g. an AI IT assistant misconfiguring infrastructure based on a false assumption) with costly results.
Malicious Tool Use by AI Agents: As organizations enable LLM-based agents to execute actions (via plugins, scripts, or API calls), a new risk emerges: the AI might misuse its tools if prompted maliciously. While we’ve yet to see a headline-grabbing public case of an AI agent creating a major security breach, researchers have demonstrated the potential. For instance, one study showed that a GPT-based agent could autonomously exploit a known software vulnerability given the right prompts[7][8]. We can imagine an agent with system access being tricked into running destructive shell commands or exfiltrating data. It’s only a matter of time before “rogue AI agent” breaches become real incidents.
These examples illustrate that AI incidents span a spectrum – from data leaks and policy violations to financial fraud and safety/control failures. Critically, they often occur without any traditional cyber intrusion. There’s no malware dropping on a server, no exploit in the code per se. The AI system behaves insecurely because of a prompt or a subtle manipulation of its inputs or context. This means security teams might have no signature to catch, and after the fact, they’re left asking: What exactly happened inside the model?
Why Traditional IR Tools Are Insufficient for AI
Traditional incident response relies on evidence like server logs, network traffic, file system changes, and malware signatures. But in an AI incident, the “crime” occurs in the model’s behavior and decisions – which often go unrecorded by standard IT logging. Attila Rácz-Akácosi, an AI security researcher, describes it well: investigating a compromised AI is like dealing with a “ghost in the machine,” because the crucial evidence – such as the prompt that triggered a bad outcome – is ephemeral and often not captured anywhere[9]. Key differences that handicap conventional IR include:
Ephemeral and Unlogged Inputs: Unlike a code injection that might be logged in an application server log, a prompt injection may leave no trace. By default, many AI platforms do not log the full prompt and response content due to privacy or storage concerns. If your monitoring only shows an API call to an LLM service, you know that someone queried the model, but not what they asked or what the model replied. If the model output something toxic or leaked data, without prompt logging you have no “murder weapon” to inspect[10]. Traditional SIEMs and application logs were never designed to record a textual conversation between a user and an AI.
Opaque Reasoning (“Black Box” Models): Even if you have the prompts, understanding why the model did something can be non-trivial. Large models don’t have explicit decision trees or rules; their “thought process” is buried in millions of weight parameters. We can’t simply put the model on a witness stand and ask why it produced a particular response[11]. This makes root-cause analysis challenging – was it a poisoned piece of training data? A flaw in the prompt instructions? Or just a stochastic fluke? The forensic analyst must piece together clues without the benefit of clear explainability from the model.
Lack of Event Boundaries: In a complex AI pipeline (e.g. an autonomous agent that consults a vector database and calls external APIs), the “events” of interest are the AI’s internal decisions: which document did it retrieve? Which tool did it invoke and with what parameters? These aren’t captured in system logs unless you’ve instrumented the AI framework to emit them. Traditional IR might tell you that a certain API key was used to access a database, but not that it was an AI agent – acting on a malicious instruction – that triggered the access. The timeline of an AI incident exists largely outside the purview of normal monitoring tools.
Dynamic, Evolving Systems: AI models aren’t static code – they can be updated or fine-tuned frequently, sometimes even learning and changing behavior in real-time. This complicates investigations. The model state that produced a malicious output last week might have been overwritten by a new version this week[12], potentially erasing forensic evidence of the prior behavior. Traditional IR assumes a relatively fixed system state during evidence collection, but with AI you must account for a moving target. Investigators may need to retrieve a specific model checkpoint or version to reproduce the event – if that version isn’t tracked and stored, the evidence is lost.
In short, classic IR tools leave us “flying blind” during AI incidents. As one expert bluntly advises: “You MUST log the full, raw prompt and the full, raw response. Without this, you have no murder weapon… You can’t analyze a prompt injection if you didn’t save the prompt!”[10]. Likewise, you need a record of what context the model had, which model version was running, and what downstream actions were taken. Unfortunately, most organizations haven’t implemented such granular logging for their AI systems yet. This gap means a breach involving an AI (say an LLM that discloses customer data) can be extremely difficult to investigate after the fact – an alarming prospect for CISOs and IR leads.
Reconstructing the Incident: Prompt to Outcome
When an AI incident occurs, one of the first challenges is reconstructing the sequence of events that took place inside the AI system. Security teams should strive to build a timeline like: What prompt or input started it? What context or knowledge did the model have at that time? What did the model respond? Did it call any tools or perform any actions? And what was the final outcome? This is the AI equivalent of tracing an intruder’s steps through a network – except the intruder here may be an AI’s own decision process.
A useful mental model is to break the AI’s behavior into a chain of discrete elements that an investigator can analyze. The incident timeline might be represented as follows:
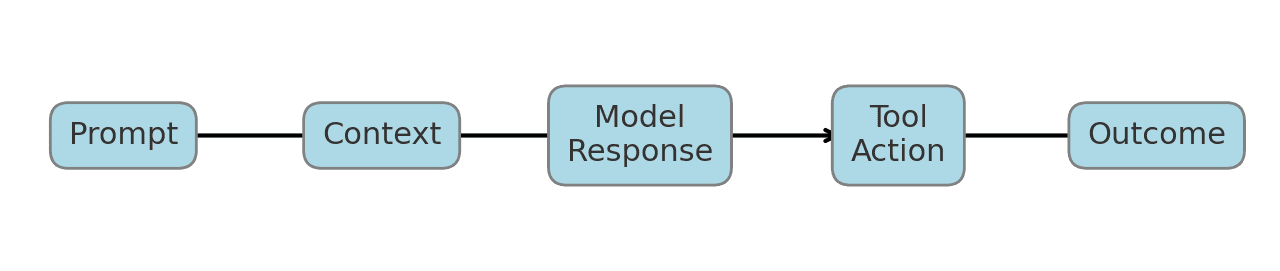
Figure: Conceptual timeline of an AI incident, from the initial prompt through to the outcome. In an AI forensic investigation, we want to capture each step: the user’s Prompt (or attacker’s input), any Context provided to or retrieved by the model (e.g. documents from a knowledge base or system instructions), the Model Response (the AI’s output text), any Tool Action the AI took (calls to plugins, APIs, file operations, etc.), and the final Outcome. By reconstructing this chain, responders can pinpoint where things went wrong.
In practice, building this timeline requires that your AI system be instrumented to log those components. Consider a scenario where an autonomous support agent made an incorrect refund: The forensic timeline would include the customer’s chat message (prompt), the internal knowledge base entries the agent looked up (context), the agent’s response instructing a refund (model output), the calls it made to the billing API (tool actions), and the result (outcome) of a $500 refund issued. Each link is crucial. Did the prompt itself explicitly tell the AI to do something unintended? Did a retrieved document contain a malicious instruction that the model followed (an indirect prompt injection)? Was the model’s response improperly formatted or over-confident in granting the request? Without a timeline, these questions stay unanswered.
Notably, many AI incidents boil down to prompt-context-response mismatches – the model did something undesirable given a certain prompt and context. Timeline reconstruction surfaces these mismatches clearly. It also helps in distinguishing cause from effect. For instance, if an agent took a destructive action, was it because the model’s response was malicious, or because the response was fine but a downstream tool mis-executed it? By tracing prompt → response → action, you can see where the fault originated.
Some organizations are beginning to recognize this need. AI security solutions now advertise features like “provenance tracking” or event chain reconstruction, e.g. logging which prompt, which model, what context, and what result[13][14]. The goal is to enable investigators to replay or analyze the incident step by step. In essence, an AI incident responder needs to become part detective, part data archaeologist – sifting through conversation logs, embedding vector search results, and system call traces to piece together the AI’s behavior. Having a well-defined timeline model like Prompt → Context → Model Response → Tool Action → Outcome focuses this effort and ensures you’re gathering the right evidence for each link in the chain.
Forensic Readiness: Logging and Evidence in AI Systems
To effectively investigate and respond to AI incidents, organizations must build forensic readiness into their AI platforms. This means having the mechanisms in place to capture relevant data and retain it for analysis. Let’s break down the key components that an AI/ML security owner or SOC team should implement:
Prompt and Response Logging: At minimum, log every user query (prompt) sent to your models, along with the model’s output. This logging should be verbatim and ideally stored in a secure, append-only datastore for audit purposes. As noted, without prompt logs you’re left helpless in diagnosing prompt injection or hallucination issues[10]. Include system prompts or hidden instructions as well – basically any input that the model saw. If privacy or compliance is a concern (since prompts might contain sensitive data), treat this log like other sensitive audit logs: encrypt it, restrict access, and purge after an appropriate retention period. Some AI API providers offer an option to log or retrieve conversation histories – use it. In self-hosted models, ensure your application layer captures the prompt/response around each inference.
Context Traceability: Many advanced AI applications supply additional context to the model, beyond the user’s prompt. Examples include documents retrieved from a vector database (in RAG pipelines), data from a user profile, or the state from previous conversations. It’s critical to log what context was provided or retrieved at inference time. For instance, if your bot pulled three knowledge base articles to answer a question, record the IDs or content of those articles. If a system or developer prompt is prepended (for persona or policy), log that too. This allows investigators to see if perhaps a piece of context contained a malicious instruction or incorrect info that led the model astray. In one attack on Slack’s GPT-based assistant, the exploit hinged on the model being tricked by a hidden snippet of text in a channel[5] – something you’d only catch if you knew which context the model was using. Having a trace of context also helps in reproducing the incident later (feeding the model the same documents and prompt).
Model Version Pinning and Metadata: Always know which model (and which version) produced a given output. This sounds obvious but can be non-trivial if you frequently update your models or use external APIs that might upgrade the model behind the scenes. Encourage your ML platform team to use explicit versioned endpoints or model IDs. Log the model name/version or a hash of the model weights for each request. This ties into supply-chain integrity as well – you want to be able to verify if the model itself was tampered with. In a sophisticated attack, an adversary with access could subtly alter model weights to insert a backdoor. It’s good practice to keep checksums of your model files[15] and validate that the deployed model hasn’t changed unexpectedly. At the very least, if an incident is suspected to be caused by model behavior, pinning the version allows you to load that exact model later to reproduce and analyze the output (since a newer model might not misbehave in the same way). Model metadata like hyperparameters and system settings also matter – e.g., was the model running in a high-creative mode that allowed it to ignore instructions? Log any non-default settings (temperature, system prompt content, etc.) that might affect outputs[16].
Agent Action Trails: If your AI system can take actions (autonomous agents or tools/plugins invoked by the model), treat those actions as part of the critical audit trail. This includes logging any function call the model tries to execute, external API requests it triggers, database queries it makes, or files it creates. For example, if an AI assistant uses a “EmailSender” plugin to send emails on behalf of users, log the fact that on prompt X, it called EmailSender with parameters Y. Traditional application logs might capture the outbound API call, but they won’t necessarily tie it back to the AI’s decision. You may need to instrument at the AI orchestration layer (like the agent framework) to emit these logs. When investigating an incident, these agent/tool logs let you see the consequences of the model’s response. Perhaps the model itself didn’t output sensitive data, but it instructed a tool to fetch and send sensitive data elsewhere – without tool logs you’d miss that. Many AI incidents will involve a combination of text and action, so both need to be captured.
Secure Log Storage and Provenance: All the logs mentioned – prompts, context, responses, actions – should feed into a secure logging system. Consider using a dedicated AI provenance store or tagging these events clearly in your SIEM for easy correlation. Protect these logs from tampering (they might be needed as evidence for legal or compliance investigations if an AI causes a significant breach). Some organizations implement a “ledger” system for AI transactions, recording each step with a cryptographic timestamp to ensure integrity. The overhead is worthwhile if your AI is handling high-risk transactions. Remember that an AI’s output could itself be an attack (e.g., telling a user to do something fraudulent); preserving the exact output is key for post-incident analysis and for retraining or patching the model to prevent repeats.
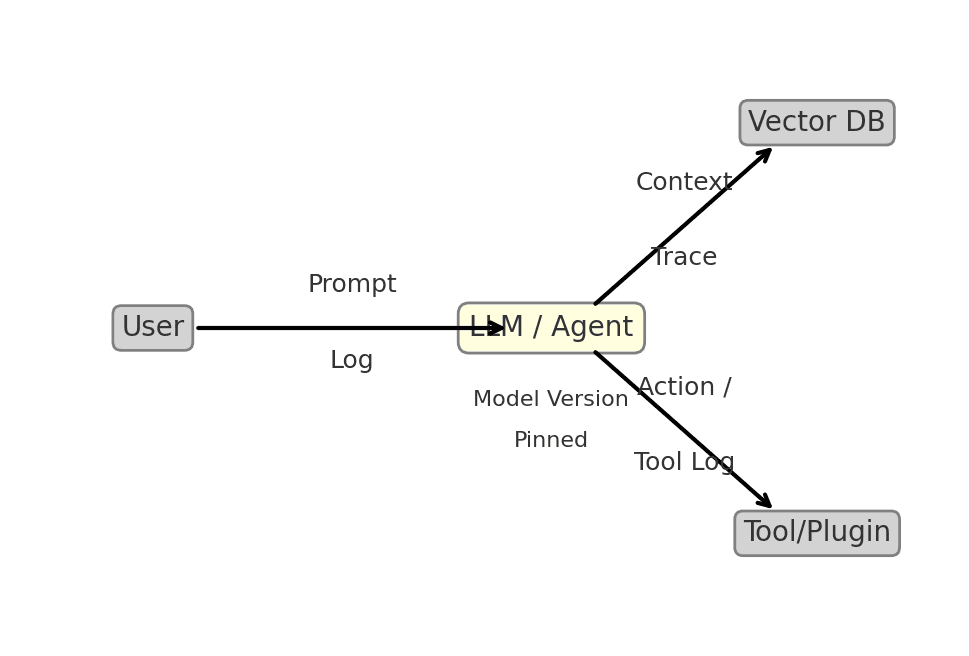
Figure: An instrumented AI architecture for forensic readiness. By logging the Prompt and model Response, capturing any Context retrieved (from a vector DB or knowledge base), recording Tool/Plugin calls (actions the AI takes), and tagging the Model Version, security teams gain the visibility needed to investigate AI incidents. These log streams should feed into your monitoring and be available for timeline reconstruction. (In this diagram, the user’s query and the AI’s answer are logged; the AI’s integration with a vector database and an external tool are also traced, and the model version is noted for reference.)
· Environmental and Traditional Logs: It’s worth noting that AI forensics doesn’t replace traditional DFIR practices – it augments them. You should still collect system logs, network telemetry, and cloud activity logs as you normally would[17]. Often, these will show the boundary of an AI incident. For example, your cloud logs might show that an API key was used to access thousands of records (alerting you to a possible data leak) – but the AI provenance logs will explain why (maybe an AI agent was compromised by a prompt to exfiltrate data). In the “Three Layers of AI Forensic Evidence”[18] described by AI security experts, Layer 1 is the environment (system and network logs), Layer 2 is the AI interaction (prompts, responses, etc.), and Layer 3 is the model internals (weights, training data). For readiness, ensure Layer 2 is not neglected. Many organizations have robust logging for Layer 1, and maybe even version control for Layer 3, but completely lack Layer 2 logging. The investments above aim to close that gap.
By establishing these logging and data collection practices, you set the stage for effective incident response. It’s analogous to installing CCTV cameras (prompt logs), maintaining access logs to sensitive rooms (tool usage), and version-tracking your vault’s combination (model version) in a traditional security setup. It gives your responders the critical evidence to follow the AI’s trail when something goes wrong.
Preparing Your SOC for AI-Related Incidents
Having the data is essential, but handling AI incidents also requires new skills and processes for your security team. A mature approach will include preventive measures, detection capabilities, and response playbooks tailored to AI. Here are practical recommendations for SOCs and IR teams to get ready:
Educate and Train the Team on AI Attack Vectors: Your analysts and responders should be aware of how prompt injections, model manipulation, and AI agent exploits work. Incorporate AI scenarios into your regular training. For example, run a tabletop exercise on a prompt injection attack: an attacker tricks an HR chatbot into revealing private employee data. Walk through how the team would detect and investigate that. Red team your AI systems regularly – have internal or external testers attempt malicious prompts and see how your models and logging hold up[19]. This not only tests the model’s guardrails but also tests your monitoring: did anyone notice the suspicious prompts or the odd responses? Companies are already adopting “AI red teaming” as a service to probe these weaknesses continuously.
Expand Monitoring to Include AI Telemetry: Integrate the logs and data from your AI systems into your monitoring and alerting workflows. This might mean creating new dashboards or queries in your SIEM to correlate AI events with security events. For instance, you could set up an alert for “LLM responded with a message containing sensitive data” or “AI agent downloaded 1000 records in a short time”. Some forward-leaning security teams are developing behavioral baselines for AI agents, so that if an AI service account suddenly accesses an unusual amount of data or a new resource, it’s flagged[20][21]. It’s similar to user behavior analytics, but for an AI identity. Leverage any tooling from AI security startups or cloud providers that can detect known indicators (like the signatures of popular prompt injection exploits[22][23]). And ensure your incident detection playbooks include AI scenarios – e.g., your tier-1 analysts should know that a “suspicious output from an AI system” is something to escalate, not ignore.
Develop AI-Specific IR Playbooks: Extend your incident response plan to cover incidents involving AI systems[24]. This includes defining procedures for detection, containment, eradication, recovery, and post-mortem specifically in the AI context[25]. For detection, list the types of alerts or reports (user complaints, abnormal AI outputs) that would trigger the playbook. For containment, you might pre-plan actions like “disable the AI chatbot’s access to production data” or “switch the AI to read-only mode” if a breach is in progress. Remember that containment could involve non-traditional steps such as turning off model access keys or rolling back to a safer model checkpoint. In eradication and recovery, if a prompt injection is persistent (e.g., stored in the AI’s conversation memory or in a poisoned knowledge base), you’ll need steps to remove or neutralize the malicious input[25] – perhaps clearing the conversation context or cleaning the contaminated data source. If a model itself was compromised (via weight tampering or poisoning), recovery might mean retraining from a clean state. Your playbook should also note communication pathways: if an AI incident spills customer data or causes user-facing errors, involve corporate communications and legal for breach notification just as you would in a traditional incident.
Pinpoint Roles and Expertise: Ensure your IR team knows who to call when an AI incident happens. This could be an internal machine learning engineer or a dedicated “AI safety” team if you have one. In many cases the responders will need help from those who understand the AI system’s design. You might also arrange an on-call contract with your AI vendor or a specialized AI IR firm for support (much as companies have retainer agreements with IR consulting firms for cyber incidents). Time is of the essence in incidents, so having experts who can quickly analyze a model’s behavior or suggest remediation (like applying a new prompt filter or disabling a problematic feature) is invaluable. Some organizations are even creating “AI incident response” retainers – analogous to traditional DFIR retainers – where experts can be engaged 24/7 to handle AI-specific breaches[26][27].
Limit the Blast Radius Proactively: While this strays into prevention, it’s worth mentioning because it makes IR easier. Apply the principle of least privilege to your AI systems before something happens. For instance, if an AI agent shouldn’t need to modify certain data, make sure its credentials can only read, not write. If a chatbot never needs to view certain sensitive fields, keep those out of its context. This way, even if the AI is tricked into a bad action, the impact is contained. Similarly, implement throttles and sanity-checks: an AI-powered process shouldn’t be able to, say, issue 1000 refunds in one minute without human review. Many of these controls will prevent incidents or at least buy time for detection. In the event of an incident, they also mean fewer things for the responders to clean up. Think of it as blast-radius reduction – a core part of resilient design that pays off during IR.
Incident Learnings and Model Updates: After any AI-related incident or near-miss, conduct a thorough post-incident review and feed the learnings back into both your security controls and the AI model itself. For example, if a prompt injection got through, you might strengthen your input validation or add that attack prompt to a blocklist. If an AI gave a dangerous recommendation, consider adding a safety check so that particular advice can’t be given again. Many teams are now maintaining “prompt vaults” of known bad inputs to test against their models regularly (similar to regression tests)[19]. Also update your monitoring rules based on what you learned – incidents often reveal new patterns that can be detected earlier next time. Finally, share knowledge with the community when possible. AI security is evolving fast, and organizations collectively benefit by reporting novel incidents or attack techniques, which can inform guidelines (like the OWASP Top 10 for LLMs) and vendor improvements.
By taking these steps, a security team can significantly increase its preparedness for AI incidents. It’s about translating classic IR best practices into the AI domain: know your assets (what AI systems and data you have), instrument them for visibility, practice your response, and continually improve. As one CISO put it, “embrace AI, but do so with eyes open and guardrails on”[28][29]. With the right incident response strategy, even when your model “lies” or goes off script, you won’t be left in the dark – you’ll have the evidence and processes to respond swiftly and decisively, minimizing damage and learning from each event.
Conclusion
AI systems bring immense productivity and capability, but also a new dimension of risk. When an AI-driven incident strikes – whether it’s a data leak caused by a leaked prompt or a business disruption from a rogue AI action – organizations must be ready to investigate and respond just as rigorously as they would to a network intrusion. Traditional security infrastructure provides an essential foundation, but it must be augmented with AI-specific logging, expertise, and playbooks.
Investing in AI forensic readiness is akin to preparing a digital “black box” for your intelligent systems. It enables you to answer the tough questions after an AI failure: What exactly did the AI see and do? Why did it make that decision? And how do we prevent it from happening again? By building detailed prompt/response logs, context audits, and action trails, and by training your team to use them, you turn AI from an opaque wildcard into a manageable component of your enterprise risk profile.
In the end, successful incident response for AI systems will blend the old and the new. We still root-cause issues, contain threats, and improve our defenses – but now our analysis might trace through a conversational AI’s memory or an agent’s tool-use log. The organizations that get ahead of this curve will be the ones who can confidently deploy AI at scale, knowing they have the means to detect its missteps and the resilience to recover from them. AI is not only transforming business and IT, but also security operations: it’s up to security leaders to ensure that when the model lies – or errs or is exploited – we’re equipped to uncover the truth and respond effectively.
Sources: The insights and examples in this paper were drawn from a range of emerging best practices and reported incidents in AI security, including public incident retrospectives[2][3][4][5], expert analyses on AI forensics[9][10], and guidance on adapting IR plans for AI contexts[24][25]. As the AI threat landscape evolves, staying informed through such resources will be vital for keeping your incident response strategies up-to-date.
[1] [13] [14] [26] [27] Oximy - Security (2).docx
file://file-AU6ymDRPpxqryHp5ad6zdB
[2] [3] [4] [5] [6] 8 Real World Incidents Related to AI
https://www.prompt.security/blog/8-real-world-incidents-related-to-ai
[7] LLM Agents can Autonomously Exploit One-day Vulnerabilities - arXiv
https://arxiv.org/html/2404.08144v1
[8] Agentic AI security breaches are coming: 7 ways to make sure it's ...
[9] [10] [11] [12] [15] [16] [17] [18] AI Forensics: Evidence Collection and Analysis After a Successful Attack | Attila Rácz-Akácosi | Independent AI Security Expert, LLM Safety Specialist
https://aiq.hu/en/ai-forensics-evidence-collection-and-analysis-after-a-successful-attack/
[19] [24] [25] LLM Security in 2025: Risks, Examples, and Best Practices
https://www.oligo.security/academy/llm-security-in-2025-risks-examples-and-best-practices
[20] [21] [22] [23] [28] [29] Rogue AI Agents Are Already Inside Your Network | Cyber Sainik
https://cybersainik.com/rogue-ai-agents-are-already-inside-your-network/
Related Posts
View All


