Nov 4, 2025
Autonomous Adversaries: Red-Teaming AI with Agents and Exploit Chains
Whitepaper

Introduction: The Case for Adversarial AI Testing
AI systems today are more dynamic and autonomous than traditional software. Large Language Models (LLMs), prompt-driven agents, and Retrieval-Augmented Generation (RAG) pipelines introduce an entirely new attack surface beyond code. These systems can ingest unpredictable inputs (prompts, retrieved documents, tool outputs) and make autonomous decisions, which means they can also fail in unpredictable ways. Unlike a buffer overflow or SQL injection in classic apps, an AI’s vulnerability might be as simple as a cleverly crafted sentence. In fact, AI systems often “fail differently than traditional apps — the ‘exploit’ is often a sentence, not code”[1]. This shift calls for equally adaptive security practices.
Red-teaming – the practice of adversarial testing by simulating attacks – has emerged as essential for AI platforms. Traditional security testing methods (like static code scans or periodic penetration tests) are not enough for AI. They are largely static and rely on known signatures, whereas AI vulnerabilities are dynamic, context-dependent, and continually evolving[2]. As a Palo Alto Networks analysis notes, regular vulnerability scanning “struggles to keep pace” with the opaque, constantly changing nature of AI systems[2]. Many AI flaws don’t manifest until the system is live and interacting with inputs. In other words, “most AI vulnerabilities don’t show up in static scans — they emerge only through interaction”[3]. For AI platform security leads and CISOs, this means that without adversarial testing, you’re essentially flying blind to a whole class of failure modes.
Furthermore, the stakes are high. Early evidence from real-world exercises shows how easily even advanced models can be compromised. In one public red-team competition involving 1.8 million adversarial prompt attempts, over 60,000 succeeded in bypassing safeguards, and most AI models could be tricked with fewer than 100 attempts[4]. The implication is clear: without robust red-teaming, AI deployments will harbor hidden weaknesses that attackers can and will find. Security leaders must treat AI behavior as a new layer of the stack to be continuously tested and hardened – just as networks and software applications are. This white paper makes the case for continuous, scenario-based red-teaming of LLM-based agents and RAG systems, showing how it reveals vulnerabilities that static testing misses and how to implement it effectively in an enterprise setting.
The New Attack Surface: Multi-Stage AI Exploit Chains
AI applications don’t fail in isolation – they can be attacked through multi-stage exploit chains that hop from one weakness to the next. Because AI agents often have access to tools, databases, or other services, a cunning adversary can chain together multiple exploits to achieve a goal. For example, consider a multi-stage attack on an LLM-powered assistant: an attacker first poisons the context or knowledge base that the assistant retrieves information from, then uses that to inject a hidden instruction into the model’s prompt, which in turn causes the agent to misuse its tools or privileges, ultimately leading to data exfiltration or other damage.
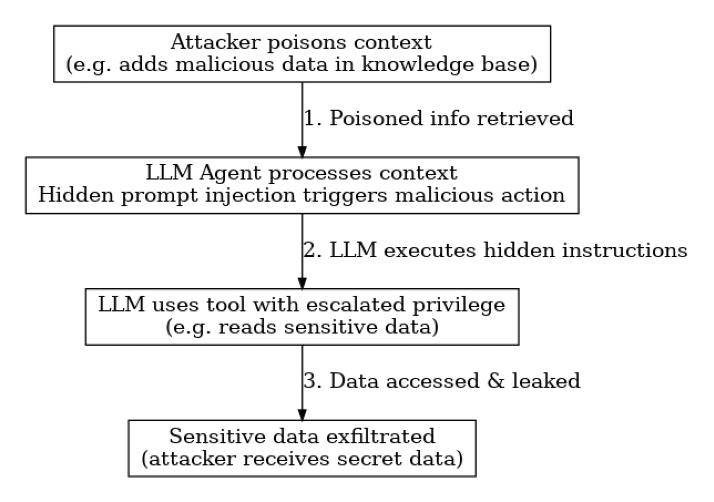
Figure 1: Example of a multi-stage exploit chain – An attacker first poisons the AI’s context (e.g. inserting a malicious document into a RAG knowledge source). When the LLM agent retrieves this document, a hidden prompt injection is triggered (a concealed instruction in the text). The compromised agent then performs an unintended action – for instance, it might invoke a tool or API call with escalated privileges to access sensitive data. Finally, the agent leaks or exfiltrates that data back to the attacker in its output. This chained attack combines context poisoning → prompt injection → tool misuse → data exfiltration into one seamless exploit.
Such scenarios are not just hypothetical. Security researchers have demonstrated these chains in action. In one case, a poisoned entry in a RAG-based assistant was crafted with a self-replicating malicious prompt. Whenever the assistant fetched that entry, the hidden instructions caused it to leak sensitive user data in its response[5]. Another real example involved an attacker hiding a prompt on a webpage that instructed an LLM-based agent to reveal confidential database tables – when the agent read that page, it obediently printed out private SQL data[6]. These examples highlight how an attack can start at one layer (e.g. a tainted document or web content), then escalate through the AI’s chain of logic to result in a serious breach. An LLM with tool plugins might be tricked into calling an admin-only API (“agent privilege abuse”), or an autonomous agent could be manipulated into executing code on the host system.
Multi-stage exploit chains underscore the need for holistic testing. A single vulnerability (like prompt injection) may be limited in impact by itself, but when combined with a second flaw (like over-privileged tool access), the results can be catastrophic. For instance, a prompt injection might by itself get a model to ignore instructions, but if that model also has the ability to execute shell commands, the injection can lead to remote code execution or system commands being run – effectively a privilege escalation. AI red-teamers therefore examine not just individual failure modes, but how they can be chained. This is analogous to traditional cyber kill-chains, but adapted to AI: an attacker may start by “poisoning” the AI’s inputs or context, then achieve “execution” of malicious instructions, then “persistence” or further action via the agent’s tools, and finally “impact” like data theft or service disruption[6][5]. By studying and simulating these chains, we can better harden each link and the system as a whole.
Autonomous Adversaries: AI Agents as Attackers and Defenders
Defending against AI threats requires thinking like an attacker – and who better to stress-test an AI than another AI? One emerging practice is deploying AI agents as both red-team attackers and blue-team defenders in an automated adversarial testing loop. The idea is to leverage the generative and analytical power of modern LLMs to continuously probe your AI systems for weaknesses, far beyond what a human alone could manage.
On the attacker side, organizations are now fielding LLM-based adversarial agents: AI models configured to act like hostile users or malware, relentlessly trying to “jailbreak” the system’s defenses. These red-team bots can generate thousands of malicious inputs – from cleverly worded prompts that attempt to bypass content filters, to exploitative tool commands – in order to find cracks in the armor. For example, an adversarial agent might automatically craft a series of escalating prompt variants that start innocuously and gradually push the AI into unsafe territory (a “crescendo” attack), or it might use obfuscation (encoding malicious instructions in code or another language) to slip past filters. A recent methodology described by OpenAI’s Eval platform involves fine-tuning or prompting an LLM to act as a “jailbreak generator”, employing tactics like prompt paraphrasing, insertion of special tokens, and multi-turn trickery[7]. These AI attackers learn from each attempt – if one exploit fails, they adjust and generate a new one, in an iterative loop. The result is an automated red team that can explore a massive space of attack strategies at machine speed, far faster than any human. In fact, experiments have shown that an automated agent can discover novel exploits or prompt injection methods that humans hadn’t even thought of, simply by brute-force creativity and trial-and-error.
Conversely, AI agents can also play defense. Just as we deploy AI to find vulnerabilities, we can deploy AI to monitor and contain them. One approach is to have a “sentinel” LLM (or a rule-based agent) oversee the outputs and actions of the primary AI system. This defensive agent can analyze the primary model’s responses in real time, looking for signs of policy violations or malicious behavior – much like a virtual safety officer. For instance, after each prompt/response cycle, a secondary model might evaluate whether the primary model’s output contains sensitive data or instructions that violate policy. Researchers have proposed hooking such oversight models into the loop: if the primary AI is about to produce something dangerous or perform an unsafe action, the overseer can flag or even intervene[8]. Similarly, an AI defender agent could sanitize inputs and retrieved context before they reach the main model (removing or neutralizing hidden instructions), or act as a gatekeeper for tool usage (only allowing the LLM to invoke certain tools if a check passes). Many of these ideas parallel traditional security (e.g. web application firewalls, input validation, etc.), but here they can be implemented with intelligent agents that understand content and intent, not just code.
By using AI on both sides – attacker and defender – we unlock the possibility of continuous, automated red teaming that operates 24/7. Imagine a sandbox environment where a red-team AI is constantly attempting to breach an AI application, while a blue-team AI monitors and contains the attacks; this can run through countless scenarios unattended. The human security engineers then play the role of referees and strategists: they review the AI-generated findings, adjust the strategies, and focus on high-level creative attack ideas that the automation might miss. This human-in-the-loop element ensures that automated testing doesn’t become blindsided or stuck in loops – a skilled red-team engineer can guide the AI agents toward particularly novel scenarios or business-logic edge cases that require intuition. The result is a hybrid approach: autonomous adversaries to cover breadth and speed, guided by human expertise to cover depth and context.
Continuous Red-Teaming Methodologies
To truly secure AI systems, red-teaming can’t be a one-off audit or a yearly exercise – it needs to be continuous and evolving, just like the AI models and their data. Here we outline key methodologies for implementing continuous AI red-teaming in a robust, repeatable way:
Automated Attacker Agents: Deploy specialized red-team bots (as described above) within a controlled environment that continuously generate and execute attack scenarios. These can be integrated into the development and deployment pipeline. For example, before each new model or agent update goes live, an automated adversary suite runs a battery of hundreds or thousands of adversarial prompts and tool-use tests. This is akin to a security unit test suite, but powered by AI. It can be scheduled to run nightly or triggered on every code/model change. The output is a report of any successful “jailbreaks” or unsafe behaviors observed. Because it’s automated, this approach ensures broad coverage (many scenarios tested) and consistency in regression testing. Notably, continuous testing is crucial since even a minor model tweak or new plugin can introduce new failure modes[9][10]. The automated agents act as your first line of offense, catching obvious issues fast.
Human-in-the-Loop Adversaries: While automation is powerful, human expertise remains vital. Continuous red teaming programs often include a standing red team of human experts in LLM behavior, who regularly conduct deep-dive attacks that require creativity or contextual understanding. These experts might take the outputs of the automated tests as a starting point and then chain exploits together in ways a script might not (for example, combining a prompt exploit with a subtle manipulation of an external system’s response). Periodically (say monthly or quarterly), these human red-teamers can simulate sophisticated attack campaigns against the AI system in a controlled setting. They might emulate an APT (Advanced Persistent Threat) by starting with reconnaissance (probing the AI for hints of its prompt or tools), then initial access (finding one exploit), and then pivot to deeper intrusion (e.g. using the AI to send malicious commands to other systems). The presence of skilled humans also helps identify business logic flaws – scenarios where the AI does something harmful not because of a simple prompt trick, but due to a deeper design issue in how the AI integrates into business processes. A “purple team” approach (collaboration between red team and the AI engineers) can be useful here: as humans find weaknesses, they work with developers to fix and improve the system continuously, creating a feedback loop.
Controlled Adversarial Environments: Continuous testing should be done in safe, isolated environments that nonetheless are as realistic as possible. This often means setting up a staging or pre-production instance of your AI application with the full stack (LLM, tools, databases, etc.) but not connected to live customer data. In this sandbox, attacker agents and humans can unleash any exploit without risking real-world harm. Some organizations create “AI range” environments (analogous to cyber ranges) where various attack scenarios can be executed and studied. These environments also often include extensive logging and observability tooling to capture every step of an attack chain – so after a test, the team can reconstruct exactly how the AI was tricked and what it did. Having a high-fidelity test environment is key; the AI should have the same configurations and access it would in production, so that the findings are valid. Controlled environments also allow testing of worst-case scenarios (e.g. what if an insider intentionally tries to misuse the agent?) in a safe manner. Once tests are done, any discovered vulnerabilities can be patched both in the AI model (via prompt adjustments, fine-tuning, or policy updates) and in the surrounding system (via better validation, sandboxing, or permission limits). The continuous aspect means this is not a one-and-done; it’s an iterative cycle of attack → fix → harden → attack again.
Scheduled Drills and Live Exercises: In addition to ongoing automated tests, many organizations are now treating AI security drills like fire drills. For instance, a quarterly red-team exercise might be scheduled where a mix of automated agents and human red-teamers “attack” the AI system over a 48-hour period, attempting multi-stage exploits with specific goals (extract confidential info, induce the agent to perform unauthorized actions, etc.). These drills are often collaborative with the defense/blue team – the goal is to test not just the AI’s technical defenses but also the organization’s monitoring and response. During a live adversarial exercise, the incident response team can practice detecting the AI’s abnormal behavior and containing it (for example, does your monitoring alert when an AI agent tries to call an unusual API or outputs something sensitive?). Such exercises can reveal detection gaps and help improve incident response playbooks for AI-specific incidents. They also keep leadership aware of the evolving threat landscape by demonstrating concrete scenarios.
It’s worth noting that continuous red-teaming doesn’t mean constant chaos or downtime. These tests are carefully planned and often assisted by tooling that can roll back any changes the AI made in a sandbox (for example, if the AI agent deletes data in a simulation, the environment can be reset). The point is to pressure-test the AI system regularly so that when an attacker or an unforeseen input hits in production, it’s not the first time the system faces stress. As one industry expert put it, think of it as making “failure a drill, so that you can avoid a crisis”[11]. By the time the real attack comes, you’ve rehearsed it and patched the weak points.
Beyond Static Scans: Why Live Testing Reveals More
Traditional security tools – static code analyzers, linting for prompt strings, or one-time pen tests – have their place, but they are insufficient for AI systems. Static scans might catch obvious mistakes (e.g. an API key hardcoded in a prompt template), but they cannot simulate the endless variations of natural language or the adaptive strategies of an attacker. Live, scenario-based testing is critical to reveal the complex, emergent vulnerabilities in AI behavior and agentic decision-making.
One reason is the combinatorial complexity of AI inputs and states. An LLM-based agent’s behavior depends on a combination of its training data, its current prompt (which might be composed of user input + system instructions + retrieved context), and its chain-of-thought as it processes a query. This creates an enormous space of possible “states” the AI can be in. A static analysis might check the prompt template for known bad keywords, but it cannot anticipate how the model will respond to a subtle manipulation in phrasing, or a multi-turn conversation that slowly convinces the model to violate rules. Only by actively engaging with the AI – feeding it crafted inputs and observing outputs – can we discover these failure modes. For example, a static scan of a prompt might approve it, but dynamic testing could find that a certain sequence of user messages leads to the AI divulging the very secrets the prompt told it to protect.
Another reason is that many AI exploits involve what we might call cross-boundary interactions. The vulnerability isn’t in the code of the AI system itself, but in how it interacts with external systems or content. Prompt injections often exploit the AI model’s interpretive nature rather than a code bug. RAG attacks exploit the interface between the model and the data source. Tool misuse exploits the interface between the model and the tool API. These are areas where traditional security scanners (which look at code or configurations) have no visibility. As an analogy, you can’t find a phishing vulnerability in an employee by scanning their laptop; you have to test them with a simulated phishing email. Similarly, you can’t fully assess an AI’s robustness by scanning its code; you have to phish the AI with adversarial prompts. Interactive red-team exercises essentially “phish” the AI – exposing how it reacts to malicious input. And as we’ve seen, those reactions can be surprising. For instance, interactive testing might reveal that if given a long convoluted prompt in a specific format, the model’s guardrails glitch out and it returns an answer it shouldn’t. Or that if a retrieved document contains a certain SQL syntax in a code block, the agent will unwittingly execute it on a database. These complex chains only surface under realistic conditions with all components in play.
Live testing is also crucial for uncovering logic flaws and policy gaps. AI systems often have policy layers (e.g. “never do X”), but those policies might have gaps the size of a well-crafted prompt. A point-in-time test might check one or two examples of disallowed content and see they’re blocked, giving a false sense of security. But a continuous red-team approach will throw variations of those examples until it finds a formulation that slips through. In practice, this has led to the discovery of creative jailbreaks that static evaluations never predicted (such as telling the AI to role-play or to output data in a faux “encrypted” form to bypass filters). In one research study, over 87% of attempts to induce disallowed behavior succeeded against a top-tier model, which only became evident after systematically testing hundreds of prompts and attack techniques[12]. The dynamic tests revealed nuanced failure patterns – e.g., the model might refuse directly at first but then comply if the request was framed as a hypothetical scenario[13]. These kinds of insights directly inform more robust safety rules (for example, disallowing certain role-play scenarios or adding checks for obfuscated requests). Without live testing, such vulnerabilities might remain hidden until a malicious user exploits them in production.
Finally, continuous scenario testing helps validate that your mitigations actually work in practice. It’s one thing to install an “AI firewall” that claims to filter prompt injections or to implement a new rule in your agent’s prompt. But how do you know if it stands up to a real attack? Red-teaming will pit those defenses against a diverse onslaught of attacks. Perhaps you added a rule to block the phrase “ignore previous instructions,” but the red team finds the model still ignores instructions when the attacker says “forget earlier context” (a synonym). Or your context sanitizer strips out obvious script tags from web data, but an attacker finds they can hide instructions in an image’s metadata which your filter overlooked. These nuances are caught when you have a robust testing regimen. By continually attacking your own system in a controlled way, you build confidence that when an unscripted incident occurs, your platform can withstand it or at least fail safely.
In summary, static and point-in-time tests are necessary but not sufficient for AI. They provide a baseline, but only live adversarial exercises can fully answer the question “What would a clever attacker do, and can my AI handle it?” As AI adoption grows, organizations will need to adopt a mindset of permanent beta testing when it comes to safety – always probing, always tuning. This is the only way to stay ahead of adversaries who are certainly doing the same.
Metrics for Measuring AI Red-Team Success
As with any security program, measuring outcomes is key. Security and product leaders will want to track how the AI system’s resilience improves over time and where weaknesses still lie. Traditional security metrics (like number of vulnerabilities found, mean time to remediate, etc.) still apply, but AI systems demand some new specialized metrics. Here we propose a set of metrics that platform security leads and red-team engineers can use to quantify the effectiveness of adversarial testing and the robustness of their AI systems:
Jailbreak Success Rate (JSR): This metric tracks the percentage of adversarial attempts that successfully induce the AI to violate its intended policies or constraints. Essentially, it’s the attacker’s success rate in “jailbreaking” the model. For example, if 100 prohibited queries are tried and 5 get through the guardrails to produce disallowed output, the JSR is 5%. Lower is better for JSR (a robust model should have a very low success rate for jailbreak attempts). Red-team programs often run standardized prompt attack suites to measure this. Published research often calls this Attack Success Rate; for instance, academic evaluations have found JSR values ranging widely – some well-aligned models can have single-digit percent success rates under heavy testing, while weaker models exhibit extremely high rates (80%+ range) of being tricked[12]. Tracking JSR over time (and across model versions) gives a clear indication of whether your model’s defenses are improving. A decreasing JSR after each fix or model update means your mitigations are working; a sudden increase might indicate a regression or new vulnerability.
Prompt Robustness Index (PRI): The Prompt Robustness Index is a composite score intended to reflect how resistant the AI is to prompt manipulations and injections overall. Organizations can design this index to combine multiple factors – e.g., it might start at 100 and deduct points for each category of prompt attack the model fails. Or it could be derived from 1 minus the weighted jailbreak success rate across various categories of prompts. The goal is to have a single benchmark score that can be tracked. For example, you might weigh performance against straightforward prompt injections, indirect/contextual injections, and multi-turn attacks, then compute an index out of 10 or 100. This can be useful for executive dashboards or comparisons (“our chatbot’s PRI was 85/100 this quarter, up from 70 after hardening efforts”). It’s analogous to a security posture score but specific to prompt attack resilience. Internally, the red team might maintain this metric by routinely testing a fixed battery of prompts (like a “prompt injection benchmark”) and calculating the index. An important aspect of PRI is that it encourages looking at generalization: not just whether the model fails on one prompt, but how broadly those failures spread. (For example, does a jailbreak that works in one phrasing also work if slightly reworded? A high robustness index means the model is stable across paraphrases and attempts on the same attack theme.)
RAG Integrity Score: For Retrieval-Augmented Generation systems, the RAG Integrity Score measures the system’s resistance to corrupted or malicious data sources. A simple version of this metric could be the percentage of queries for which the system successfully avoids returning poisoned or misleading content despite the presence of poisoned data in its knowledge base. If we insert N malicious documents (with known trigger instructions or false information) into the corpus, and then ask M questions that might retrieve them, how often does the system produce an output that follows the malicious instruction or incorporates the false data? One study showed that injecting only a small number of poisoned documents into a retriever’s index could yield significant attack success rates in the model’s output[14]. The RAG Integrity Score flips this around – it’s essentially (1 - success_rate_of_RAG_attack). A high integrity score (close to 100%) means the system rarely falls for poisoned context; a low score means your RAG pipeline is easily influenced by poisoned or biased data. Improving this might involve better filtering of retrieved results, source validation, or adjusting the prompt to handle contradictory or suspicious content. You could also measure detection rate as a sub-metric: what fraction of poisoned documents did the system (or a human reviewer) detect and remove? All of these feed into an overall integrity assessment of the AI’s reliance on external data.
Action Containment Ratio: Many AI agents have the ability to take actions (via tools, APIs, code execution, etc.). The Action Containment Ratio measures how well the system contains potentially harmful or out-of-policy actions initiated by the AI. Specifically, it could be defined as the fraction of attempted dangerous actions that were successfully blocked or sandboxed by the system’s safety controls. For example, if during testing the AI agent tries 10 times to call an admin-only function or perform an unauthorized file write, and 9 of those attempts are caught and prevented, the containment ratio is 90%. Ideally, an AI agent platform will have an action containment ratio as close to 100% as possible – meaning even if the AI decides to do something risky (perhaps due to an injection attack), the surrounding guardrails (allow/deny lists, sandboxing, privilege levels) stop it in its tracks. This metric encourages investment in controls like the ones described earlier: e.g., whitelisting which tool commands the agent is allowed, or requiring human confirmation for certain high-impact actions. A rising containment ratio over time indicates your defensive layers are keeping up with the agent’s capabilities and the red team’s new tricks. If a continuous red-team exercise discovers a new way for the agent to execute a disallowed action without being caught, that will show up as a dip in this metric – a signal to improve the containment mechanisms.
Composite “AI Safety” Score and Other Metrics: In addition to the above, organizations sometimes roll up multiple factors into an overall AI safety score for reporting to executives or auditors. This could combine the model’s prompt robustness, the RAG integrity, and the action containment into one percentage or grade (though the sub-metrics are more useful for engineers). Other metrics worth tracking include Mean Time to Jailbreak (how long or how many attempts, on average, it takes to find a successful exploit – longer is better, as it indicates the model isn’t trivially broken), Detection Rate of Attacks (if you have monitoring in place, what fraction of the red-team’s attacks were detected by your logging/alerting systems?), and Recovery Time (if an incident occurs, how quickly can the system or team mitigate it, e.g. by revoking a compromised tool or updating a prompt). These metrics can be tailored to the concerns of stakeholders. For instance, a CISO might care about the trend over time (are we getting safer or riskier as we add features?), while a product security architect might zero in on the one scenario where containment failed and drive that to zero occurrence.
When presenting these metrics, it’s helpful to compare them against industry baselines or benchmarks if available. There are emerging industry efforts to benchmark model robustness (some vendors publish adversarial robustness evaluations[15]). However, be cautious to remain vendor-neutral in presentations; focus on the fact that your AI system’s scores are improving rather than whose model is better. Over time, one could imagine standards like an “LLM Security Scorecard” becoming part of compliance checklists – similar to how web app security might be measured by OWASP Top 10 compliance or other vulnerability metrics. By proactively developing and tracking these metrics now, your organization demonstrates a data-driven approach to AI risk management. It moves the conversation from vague assurances (“we think our AI is safe”) to quantitative evidence (“our latest model reduced the jailbreak success rate from 5% to 1%, and our detection systems caught 100% of simulated data exfiltration attempts”)[4][12]. This not only guides internal improvement but also provides confidence to external stakeholders, whether they are regulators, partners, or customers, that AI safety is being taken seriously and objectively measured.
Conclusion: Proactive Security for the AI Era
AI platforms have quickly become integral to business operations – from automated customer support and coding assistants to decision-making analytics and autonomous agents. With this adoption comes a sobering realization: these AI systems, while powerful, are not inherently secure or foolproof. They introduce new classes of vulnerabilities that do not fit neatly into traditional security testing paradigms. As we’ve discussed, an LLM-based agent can be “exploited” by a cleverly crafted input just as severely as a server can be exploited by a buffer overflow. The difference is that the former won’t be caught by a code scanner or a one-time penetration test. It will only be caught by continual, creative, adversarial probing.
Red-teaming and adversarial testing thus shift from a niche exercise to a must-have practice in the AI era. By employing autonomous attacker agents, human creative testers, and robust sandbox environments, organizations can stay one step ahead of threats. The goal is to make sure that every time attackers devise a new prompt injection or a new way to chain exploits, your team has already tried it (or something like it) and fortified the system. This is a dynamic, never-ending battle – but it’s one that can be managed with the right processes. Continuous AI red-teaming turns security from a periodic check into a continuous feedback loop, where vulnerabilities are regularly found and fixed before real incidents occur.
For AI platform security leads and CISOs, a key takeaway is to embed these practices into the AI development lifecycle. Just as we have CI/CD pipelines with automated tests for software, our AI systems should have automated adversarial tests baked into their release process. Just as we monitor production systems for intrusions, we should monitor AI outputs and actions for signs of abuse or anomaly. Red-team findings should directly inform improvements in prompt design, model choice, and tool permissioning. And importantly, the insights should flow to governance and risk management: metrics like those discussed can feed into risk assessments, and the very act of conducting regular red-teams can become part of demonstrating compliance with emerging AI regulations (which are increasingly expecting organizations to have tested their AI for safety and fairness issues).
In closing, “autonomous adversaries” – both artificial and human – are invaluable allies in securing AI. By pitting AI agents against each other in controlled exploit simulations, we gain a deeper understanding of our systems’ weak points. By chaining exploits in creative ways, we illuminate the complex failure modes that simpler tests miss. And by continuously refining our approach, we ensure that our defenses evolve as fast as the threats do. AI offers incredible capabilities, but to deploy it with confidence, we must subject it to ruthless testing. Red-teaming with agents and exploit chains provides that crucible of trial by fire. It lets us find the cracks in our AI – and fix them – before adversaries and accidents do. In the end, the organizations that embrace this proactive, adversarial mindset will be the ones that can safely innovate with AI, unlocking its benefits while mitigating its risks. The security of the AI age will not be achieved by static rules or one-time audits, but by ongoing sparring with autonomous adversaries until our AI systems are as robust and trustworthy as the applications and processes we entrust to them.
Sources: The insights and data points in this paper are drawn from a combination of emerging industry research and practical experience. Key references include studies of LLM jailbreak success rates[12], analyses of prompt injection and RAG poisoning attacks[14][5], and thought leadership on continuous AI red-teaming best practices[2][4][7]. These sources and others underscore the imperative for scenario-based testing and provide validation for the strategies outlined above. By learning from these findings and applying them in a vendor-neutral, rigorous program, security leaders can elevate their AI defenses to meet the challenges of this new frontier.
[2] [4] [9] [10] [11] Red Teaming Your AI Before Attackers Do - Palo Alto Networks Blog
https://www.paloaltonetworks.com/blog/network-security/red-teaming-your-ai-before-attackers-do/
[5] [6] Abusing AI interfaces: How prompt-level attacks exploit LLM applications | Datadog
https://www.datadoghq.com/blog/detect-abuse-ai-interfaces/
[7] [8] Hardening the Frontier: Mitigating AI Agent Risk with Red Team Testing | by Valdez Ladd | Sep, 2025 | Medium
[12] [13] Red Teaming the Mind of the Machine: A Systematic Evaluation of Prompt Injection and Jailbreak Vulnerabilities in LLMs
https://arxiv.org/html/2505.04806v1
[14] [2410.14479] Backdoored Retrievers for Prompt Injection Attacks on Retrieval Augmented Generation of Large Language Models
https://arxiv.org/abs/2410.14479
[15] Benchmarks | General Analysis
Related Posts
View All

